哈喽,大家好,我是爱撸码的开源大叔!
经常在网上查询文档资料的朋友一定有过这样的经历:好不容易找到了需要的内容,可是别说下载了,连复制一句话都不给复制的。尤其是 PDF 文档和图片类资料,就算我们充值下载到本地,很多也无法复制文本,只能手动敲出来。

项目中有些场景也需要图片识别,比如识别证件、证照等等。
下面分享一款电脑端的 OCR 文字识别软件——「PaddleOCR」,可以帮助我们解决这一问题。
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力使用者训练出更好的模型,并应用落地。
特性
- 丰富易用的OCR相关工具组件
- 半自动数据标注工具PPOCRLabel:支持快速高效的数据标注
- 数据合成工具Style-Text:批量合成大量与目标场景类似的图像
- 支持用户自定义训练,提供丰富的预测推理部署方案
- 支持PIP快速安装使用
- 可运行于Linux、Windows、MacOS等多种系统
- 支持多语言OCR模型
- 支持中英文数字组合识别、竖排文本识别、长文本识别
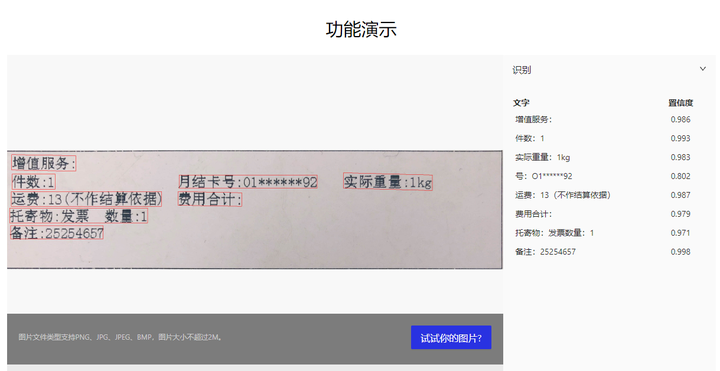
效果展示


不需要安装任何工具,可以直接在pc端进行图片识别,喜欢python的同学,可以按照下面的安装教程部署。
模型列表
| 模型简介 |
模型名称 |
推荐场景 |
检测模型 |
方向分类器 |
识别模型 |
| 中英文超轻量OCR模型(9.4M) |
ch_ppocr_mobile_v2.0_xx |
移动端&服务器端 |
推理模型/ 预训练模型] |
推理模型 / 预训练模型 |
推理模型/ 预训练模型 |
| 中英文通用OCR模型(143.4M) |
ch_ppocr_server_v2.0_xx |
服务器端 |
推理模型/ 预训练模型 |
推理模型/ 预训练模型 |
推理模型 / 预训练模型 |
还有更多模型,这里不全列举了,感兴趣同学可以去官网阅读学习。
通用中英文OCR数据集
- ICDAR2019-LSVT
- ICDAR2017-RCTW-17
- 中文街景文字识别
- 中文文档文字识别
- ICDAR2019-ArT
PP-OCR Pipeline
PP-OCR是一个实用的超轻量OCR系统。主要由DB文本检测[2]、检测框矫正和CRNN文本识别三部分组成[7]。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身,最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。
安装教程
1、安装python3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
wget https://www.python.org/ftp/python/3.6.8/Python-3.6.8.tgz
tar -zxvf Python-3.6.8.tgz
cd Python-3.6.8
./configure
make
make install
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
python3 -V
|
在安装过程中如果出现configure: error: no acceptable C compiler found in $PATH,是缺少合适的编译器
1
| sudo yum install gcc-c++
|
出现这个问题zipimport.ZipImportError: can’t decompress data; zlib not available,缺少依赖包
2、安装PaddlePaddle2.0
1
2
| pip3 install --upgrade pip
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple
|
3、克隆代码
1
| git clone https://gitee.com/paddlepaddle/PaddleOCR
|
4、安装PaddleOCR 第三方依赖包
1
2
3
| cd PaddleOCR
#安装第三方依赖项
pip3 install -r requirements.txt
|
5、模型下载
1
2
3
4
5
6
7
| mkdir inference && cd inference
# 下载检测模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar&& tar xf ch_ppocr_mobile_v2.0_det_infer.tar
# 下载方向分类器模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_infer.tar
#下载文本方向分类器病解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar && tar xf ch_ppocr_mobile_v2.0_rec_infer.tar
|
6、识别图片
1
2
3
4
| #识别单张图片
python3 tools/infer/predict_system.py --image_dir="992822f810dc3cbbdcca711a1c4b0097.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
image_dir:源文件目录 det_model_dir:识别后存放的文件目录
|
如果报错ModuleNotFoundError: No module named ‘cv2’,缺少cv2
1
2
3
4
5
6
7
8
9
10
11
12
|
wget https://pypi.python.org/packages/source/p/pip/pip-18.1.tar.gz
tar -zxvf pip-18.1.tar.gz
cd pip-18.1
python3 setup.py build
python3 setup.py install
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
pip install opencv-python
|
如果出现pip is configured with locations that require TLS/SSL, however the..不可用的解决方法
1
2
3
4
5
6
| yum install openssl-devel -y
cd Python-3.6.8
./configure --with-ssl
make
sudo make install
|
在识别图像时候报错的一些解决方案
1
2
3
4
5
6
7
8
| #深度学习
pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
# ModuleNotFoundError: No module named 'PIL'
pip install pillow
# MODULENOTFOUNDERROR: NO MODULE NAMED 'PADDLE'
pip install paddlehub==1.6.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
#No module named 'imgaug'
pip install git+https://github.com/aleju/imgaug
|
ps:Paddle-OCR也可以部署在Windows系统中。
1
2
3
4
5
6
7
| pip3 install --upgrade pip
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple
git clone https://github.com/PaddlePaddle/PaddleOCR
#在PaddleOCR目录下
pip3 install -r requirements.txt
|
总结
Paddle-OCR 属于Paddle 框架其中的一个应用,提供了很多好玩的模型,支持多种语言的数据集,关键是提供了轻量级模型,降低了使用难度。
听了大叔的介绍,各位小伙伴有没有心动?心动不如行动,赶紧去公众号后台回复「OCR」,获取开源项目的地址吧~~~

